
W uczeniu maszynowym technika embedding pozwala na znajdywanie podobnych encji (np. tekstów, piosenek, obrazów…). A wykorzystywane są przy tym wektory (można się pokusić o stwierdzenie, że embedding to wektor) wielowymiarowe.
Przykład wizualny
Załóżmy, że mamy bazę danych ludzi i kategoryzujemy ich na podstawie wzrostu i wagi:
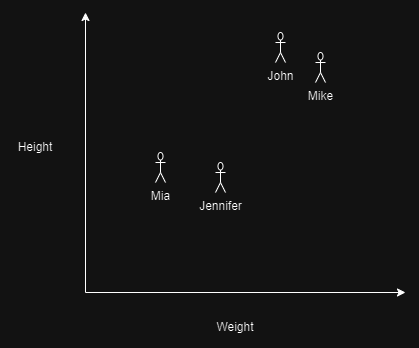
I pojawia się nowa osoba (oznaczona na zielono), i znamy jej wzrost i wagę:
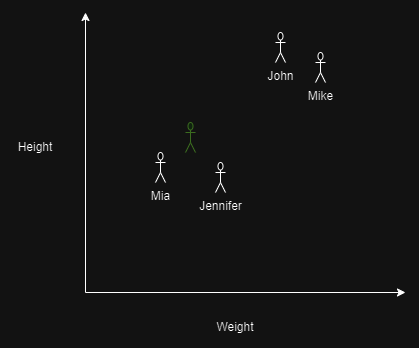
Możemy na przykład spróbować wywnioskować, że ta osoba jest prawdopodobnie kobietą.
Jak to działa w praktyce?
W praktyce sprawa sprowadza się do stworzenia wektora (embedding) dla nowego przypadku i dopasowania go, do już istniejących wektorów. Czyli mając bazę:
| Sex | Height | Weight |
|---|---|---|
| Male | 180 | 90 |
| Male | 190 | 100 |
| Female | 170 | 60 |
| Female | 160 | 50 |
I dostając dane odnośnie wagi oraz wysokości:
Height: 165
Weight: 55Możemy spróbować przewidzieć płeć osoby – tworzymy nowy wektor i szukamy najbliższych mu istniejących:
Nowy wektor:
[165,55]
Istniejące:
[180,90][190,100][170,60][160,50]
Najbliższe wektory to te przynależące do kobiet:
[170,60][160,50]